7 Hidden LLM Engineering Concepts No One Explains (But You Actually Need)
Introduction
You’ve probably used tools like ChatGPT, built a few prompts, maybe even shipped something using an LLM API, and thought, “Okay, this works. But why does it sometimes completely break?” Same here. Everything looks solid in demos, but once real users and messy inputs come in, things get unpredictable. Outputs drift, instructions get ignored, and suddenly your “smart” system feels unreliable.
However, the harsh reality is that tutorials typically focus on superficial aspects such as prompts, API requests, and adjusting temperature. In the real world, though, the tricky part is all under the hood, including structuring your context, dealing with token limitations, and making sure you can recover from model errors. This is when LLM engineering starts to happen.
In this article, I’m going to walk you through 7 hidden LLM engineering concepts that no one really explains, but you definitely need if you’re building anything serious.
1. Token Budgeting Isn’t Just About Limits
Most people think tokens are just about cost or maximum length, but that’s only half the picture. In real-world applications, token allocation is actually a strategic problem that directly impacts output quality.
However, when your inputs start getting too lengthy, it means that the model will no longer have equal treatment for all the inputs, whereby some parts, especially at the beginning, may end up being lost, making some of the commands difficult to understand or implement.
Good LLM engineering does not only involve ensuring that you do not exceed the token limit; it’s about structuring and prioritizing context so the model consistently focuses on what truly matters.
Practical example:
Let’s say you’re building a chatbot with:
- System prompt (rules)
- Chat history
- User input
If you don’t manage tokens properly, your system instructions slowly lose authority.
What I do:
- Trim chat history intelligently (not blindly)
- Keep the system prompt short but strict
- Use summarization for long conversations
2. Prompt Positioning Matters More Than Prompt Writing
Everyone speaks of what is to be written, but no one ever speaks about where it should be written, and this is where all the problems begin. Indeed, it is a fact that language models inherently pay more attention to recent tokens and well-formulated prompts, meaning that any prompt, despite how good it may be, will not work if it is placed too far ahead or poorly formulated.
Let me clear it with a practical example:
Poorly Structured SQL Query Generation
Input:
Generate a SQL query to fetch all users who signed up in the last 7 days.
We are using PostgreSQL.
Here is the schema:
users(id, name, email, created_at)
Make sure the query is optimized and only returns id and email.
Also note:
– Avoid unnecessary columns
– Keep performance in mind
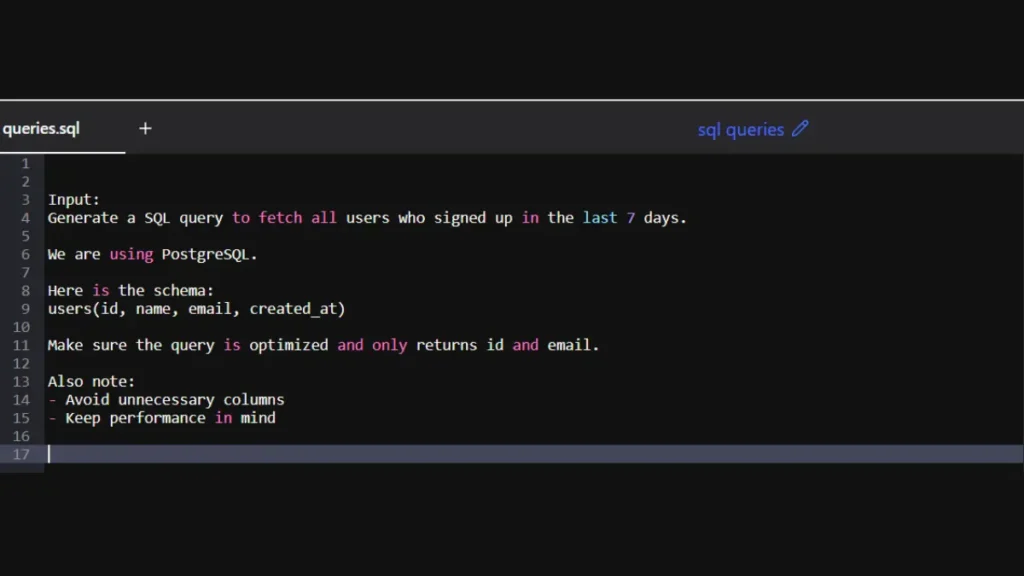
The real problem is that the actual constraint (“only return id and email”) is lost inside mixed instructions and notes. The model will return:
SELECT * FROM users WHERE created_at >= NOW() - INTERVAL '7 days';Better Structure:
You are a senior backend engineer writing production-ready SQL.
User:
Task: Fetch users who signed up in the last 7 days.
Schema:
users(id, name, email, created_at)
Assistant Instruction:
– Use PostgreSQL syntax
– Return ONLY: id, email
– Optimize for performance
– Do not use SELECT *
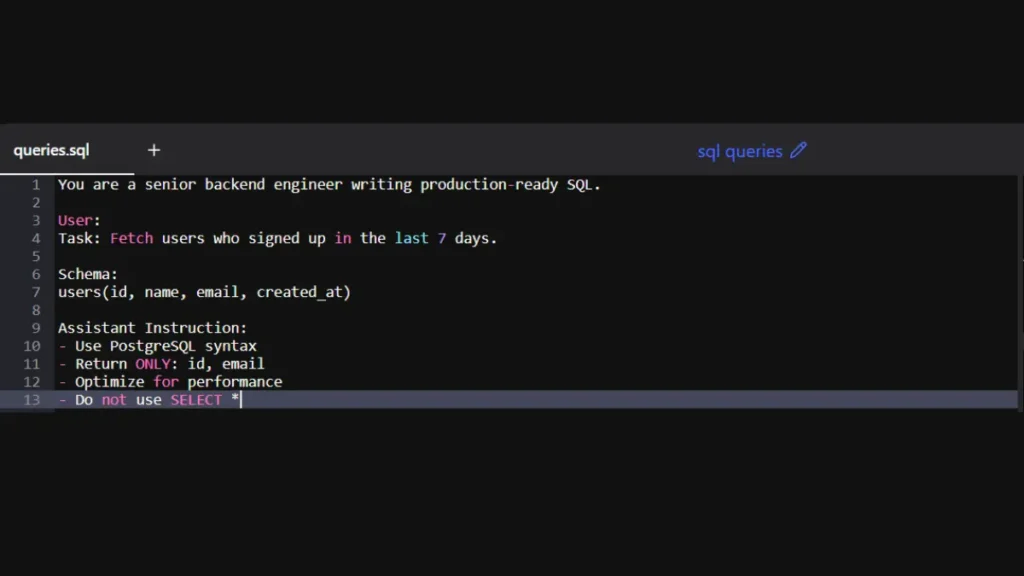
Now the output is much more reliable:
SELECT id, email
FROM users
WHERE created_at >= NOW() - INTERVAL '7 days';3. The “Lost in the Middle” Problem
This one hits harder than most people expect, especially when you start working with long-context prompts. The reason for this is that while the machine learning algorithm has a decent ability to retain what you say at the beginning, it really focuses on what you say at the end; anything in between seems to fade into oblivion.
When it is applied in real-life scenarios, this can become problematic, particularly when you provide a long piece of text to the AI model and then pose a question. Most of the time, you will receive a coherent response, but the crucial information will be missed somewhere along the way.
Fix it by chunking your data, using RAG for retrieval, and ordering content smartly. Don’t blindly trust long context. Structure it in a way that ensures critical information remains visible and prioritized.
4. KV Caching: The Invisible Engine of Inference Speed
If you’ve ever noticed a model taking a few seconds before it starts responding and then suddenly generating text rapidly, that’s the KV cache at work behind the scenes. Most tutorials treat inference like a black box, but this is where things actually get interesting.
Large language models are autoregressive, which means that the generation of the 50th token depends on processing the preceding 49 tokens. If no caching is used, then the model will have to recalculate the attention for all previous tokens every time, which makes the algorithm (O(n²)) in terms of complexity.
The Engineering Reality:
KV Cache stores previous attention computations directly in GPU memory. So instead of recomputing everything, the model only processes the new token.
That’s why:
- The first token is slow
- Next tokens are fast
The Catch (Most People Miss This):
KV cache is surprisingly memory-heavy, especially with longer prompts. As tokens grow, the cache can even exceed the model’s own size, quickly filling up GPU memory. That’s why you sometimes hit unexpected “OOM errors” even when your prompt doesn’t look that big on the surface.
What I personally do:
- Use smarter inference engines like vLLM
- Limit the unnecessarily long context
- Monitor GPU memory, not just tokens
In one of my projects, I kept getting out-of-memory errors even with relatively small prompts. After debugging, I realized the issue wasn’t the model size, it was the KV cache silently consuming GPU memory.
5. Logit Bias: The “Gentle Nudge” vs. The Hard Rule
This is where most developers struggle and often overcompensate. You’ve probably written prompts like “ONLY RETURN JSON. DO NOT ADD ANY TEXT.” and still ended up with broken output.
This is because a prompt serves only as a soft constraint, not a strict rule. Behind the scenes, before the generation of each token, the model generates logits for all available tokens. While temperature controls the randomness of the process, logit bias influences the probabilities of specific tokens.
Practical Example: Yes/No (or Positive/Negative) Classifier
Let’s say you want output strictly like:
- “Positive”
- “Negative”
Instead of relying on prompt instructions, you:
- Add +10 bias to “Positive” and “Negative” tokens
- Add negative bias to everything else
This actually works because the model cannot select anything but the tokens you’ve instructed.
Real Insight: Prompting is a polite request, but logit bias is enforcing restrictions. It’s the contrast between reminding a toddler not to touch cookies and keeping them locked up. It’s useful in situations when you require structured data, such as JSON, classifications, or filtering words. To ensure you have consistent results, use logit bias rather than yelling in your prompts.
6. Evaluation Is the Hardest Part (Trust & Credibility Signal)
Shipping a prompt is the easy part; the real challenge is knowing it still works after 10,000 runs. While with normal code there is an obvious pass-fail criterion, LLM outputs can be very messy, subjective, and kind of “vibe-based.” Unless you are actually evaluating their quality with some sort of “LLM as a judge” or benchmarking, you are just shooting in the dark. Actual engineering happens when you go beyond “it looks fine to me” and automate your evaluations to spot problems.
This becomes especially important when you’re using tools like Gemini for research tasks. If you’re not careful, the model can confidently generate incorrect insights. I’ve broken down a practical approach to avoid this in my guide on How to Use Google Gemini for Research: Complete Beginner Guide 2026
7. Constrained Generation: The Death of the “Black Box”
If your production application depends on the LLM “hoping” that it follows a schema, you are not building a system; you are making a bet. The most sophisticated notion in LLM construction is shifting from stochastic generation to bounded execution.
Most people think you have to trust an LLM to follow instructions, but that’s no longer the case. Instead of letting it generate any token freely, you can constrain it using a Context-Free Grammar (CFG) or JSON Schema. This creates a sort of guardrail around the decision-making process of the model; at every stage of the decision, only valid tokens are considered, while anything invalid gets blocked. Thus, if you want to receive a properly structured JSON, there is no way the model will generate anything outside the bounds of proper syntax.
The real shift is in how tools like Guidance, Outlines, or Instructor operate. They do not evaluate the outputs after they are generated, but manage the process as it unfolds. Each token prediction eliminates any choices that violate the constraints. If the following letter needs to be a quotation mark, the probability for other choices becomes zero. The system does not “try” to comply with the constraints anymore because it is bound to do so.
Why this matters:
- Zero Syntax Errors: You get clean, valid JSON every single time, no surprises.
- Reduced Latency: The model skips the fluff like “Sure, here is your data:” and jumps straight into the output.
- Deterministic Logic: You’re not chatting with the model anymore; you’re basically calling it like a function.
The Practical Take:
Stop asking the model to please do this right for you. Wrap it around a Finite State Machine instead. As soon as you restrict the tokens that it is allowed to generate, its “unpredictable” behavior becomes nothing more than predictable backend component.
Conclusion
As I gained more experience in developing AI capabilities, it became evident that my initial assumptions about their nature were too naive. In the beginning, building AI models seemed almost like witchcraft: you only needed to come up with a good prompt, and things would happen. However, in practice, that approach turned out to be highly unsatisfactory. It took me some time to realize that the key to success is to start looking at this process in an engineer’s way.
The biggest shift for me was treating the model less like a “smart assistant” and more like a system I can control. Once you do that, everything changes. You stop guessing and start designing for reliability. That’s the difference between something that works in a demo and something you can confidently ship. As AI keeps evolving, the edge will go to those who stop relying on luck and start building systems that guarantee results.
FAQs
If prompt engineering isn’t enough, what actually makes an LLM system production-ready?
A production-ready system relies on structured context, controlled outputs (schemas/CFG), evaluation pipelines, and fallback handling, not just better prompts. Prompts are only the interface, not the system.
How do I know if my issue is token budgeting vs. “lost in the middle”?
If important instructions disappear randomly, it’s likely token prioritization. If middle content is consistently ignored in long inputs, that’s the “lost in the middle” problem.
When should I use RAG instead of just increasing context length?
Use RAG when relevance matters more than volume. Dumping more context increases noise, while retrieval ensures only the most useful information is seen by the model.
Is KV caching something I need to worry about if I’m just using APIs?
Not directly, but indirectly yes. It affects latency, cost, and scaling. If your app slows down or hits memory limits at scale, KV cache behavior is often the hidden reason.
Why does my model still break JSON even with strict instructions?
Because prompts are soft constraints. To guarantee structure, you need constrained generation (like JSON schema or CFG), not just instructions.
How do I evaluate LLM outputs when there’s no clear “right answer”?
Use a mix of strategies: LLM-as-a-judge, benchmark datasets, and task-specific scoring. The goal is consistency and trend tracking, not perfect accuracy.
What’s the biggest mindset shift from demo AI to real AI systems?
Stop treating the LLM like a “smart assistant” and start treating it like a probabilistic component inside a deterministic system. You design the boundaries, it doesn’t.


